
Smarter Search at Airbnb: How Embedding-Based Retrieval Works
A short guide to embedding-based retrieval fundamentals
Stacksweep is a newsletter on staying up to date and interview-ready on practical software engineering fundamentals with real-world examples.
Airbnb revamped its search system using something called Embedding-Based Retrieval (EBR) — a technique from machine learning that helps narrow down millions of listings to a much smaller, more relevant set. (Source)
The Challenge: Relevance at Scale
Airbnb’s mission with search is simple: help guests find the right place. But in reality, it’s very hard.
There are millions of listings, and user queries vary wildly. For example:
Some users search “New York” while others search “cozy cabin with fireplace in the Catskills.”
Some don’t even choose fixed dates (thanks to flexible search options).
This makes it difficult for traditional search systems, which often rely on keyword matching or filters, to provide great results quickly.
Airbnb’s key insight: What if we used deep learning to represent both listings and search queries as vectors in the same space, and then just searched for vectors that are close to each other?
This is the idea behind Embedding-Based Retrieval.
What Is Embedding-Based Retrieval (EBR)?
Embeddings are numerical representations of things — like listings or user searches — in a multi-dimensional space (think of a map with hundreds of axes instead of just X and Y). Things that are similar (like a guest’s query and a matching home) end up close together in that space.
Retrieval is the process of pulling relevant candidates from a huge database of possibilities. With EBR, Airbnb retrieves listings that are “close” to a query in embedding space.
This gives Airbnb a fast, scalable way to narrow millions of listings down to a much smaller set before doing expensive final ranking.
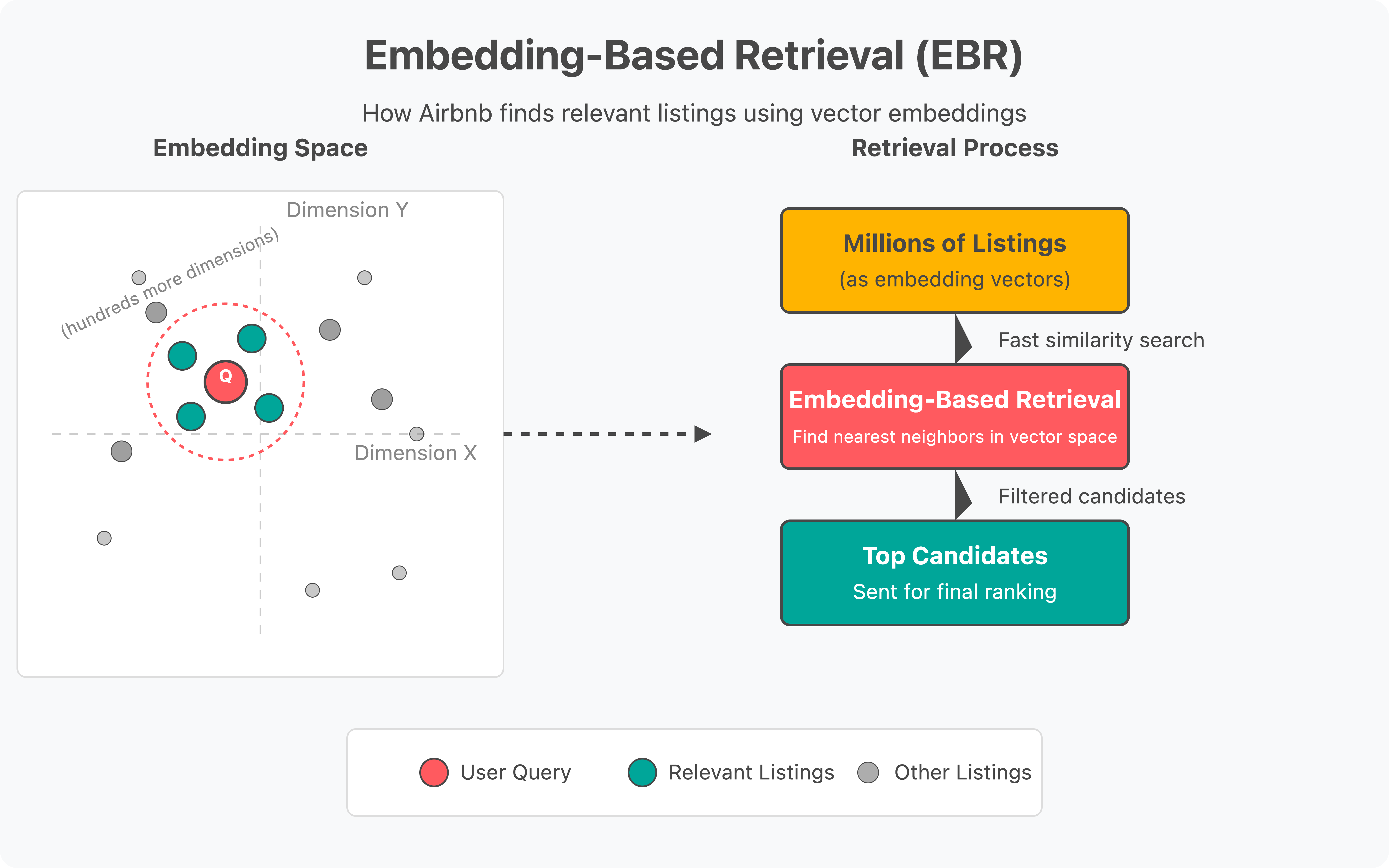
For example, a "beachfront condo in Miami" and a "seaside apartment in South Beach" might be far apart in keyword space but close in embedding space because the model understands they're conceptually similar. Meanwhile, a "beachfront condo in Miami" and a "ski chalet in Aspen" would be far apart in embedding space despite both being vacation properties.
🛠 Step 1: Constructing Training Data
To train their EBR model effectively, Airbnb needed a sophisticated approach to generate high-quality training examples:
Trip-Based Query Grouping
They defined a "trip" as a collection of related historical queries made by a user who eventually completed a booking. Queries were grouped based on key parameters: geographic location, number of guests, and length of stay. This approach allowed them to capture the entire multi-stage search journey most users undergo before booking
Positive and Negative Sample Selection
The listing ultimately booked by the user became the positive example
For negative examples, they carefully selected listings the user encountered but didn't book:
Listings that appeared in search results but weren't selected
Listings the user interacted with more deeply (clicked into details, read reviews)
Even listings the user added to wishlists but ultimately didn't book
Strategic Sampling Rationale
Random negative sampling was deliberately avoided as it would make the learning task too easy. By using listings the user actively considered but rejected, the model learned to distinguish between subtle preference signals. This approach acknowledges that users typically explore multiple options through various search sessions before making a final decision
Contrastive Learning Implementation
The model was trained to map queries, positive homes, and negative homes into a numerical vector space. The training objective pushed query embeddings closer to positive listing embeddings. Simultaneously, it increased the distance between query embeddings and negative listing embeddings. This contrastive approach helped the model capture nuanced user preferences beyond simple keyword matching
👉 Key concept: In ML, contrastive learning helps models understand similarity by comparing good vs. bad examples in the context of a task.
🧱 Step 2: Designing the Model — Two-Tower Architecture
Airbnb used a two-tower model architecture, which is common in retrieval systems.
Tower 1 (Listing Tower): Inputs info about the home — location, number of beds, past guest ratings, etc.
Tower 2 (Query Tower): Inputs info about the search — where the guest wants to go, how many people, how long the stay is.
Each tower turns its input into an embedding. During training, the goal is for the query and the right listing to end up close together in embedding space.
For instance, when a user searches for "Family home near Disneyland, 2 adults, 3 children, July 15-22":
Query Tower processes: Location (Anaheim area), Group size (5 people), Dates (7 nights in July), Implied need (family-friendly)
Listing Tower might have pre-computed embeddings that represent: "3-bedroom home in Anaheim, sleeps 6, pool, family-friendly, high summer availability"
The system calculates similarity and finds these embeddings are close in the vector space, making this listing a strong candidate.
💡 Cool trick: The listing tower is computed offline once per day. That means Airbnb doesn’t need to recalculate embeddings for listings in real time, saving lots of compute during live searches.
👉 Key concept: Two-tower models are ideal when one side (like listings) can be pre-computed and stored, while the other side (like user queries) must be computed on the fly.
⚡ Step 3: Fast Retrieval with Approximate Nearest Neighbors (ANN)
Once listings and queries are embedded, Airbnb needs a way to quickly find the closest listings for any given query. That’s where ANN search comes in.
What is ANN?
Instead of checking every possible vector (slow), ANN finds “good enough” nearby vectors fast.
Airbnb evaluated two popular methods:
HNSW (Hierarchical Navigable Small World graphs): Great accuracy, but high memory usage and latency when filters (like location) are applied.
IVF (Inverted File Index): Slightly lower accuracy, but much faster and more memory-efficient when filters are used.
They chose IVF — it let them group homes into clusters and then just search the clusters most relevant to the query.
How IVF works in practice:
Offline: Airbnb groups all listing vectors into clusters (think "beach houses," "urban apartments," "mountain cabins")
When a search comes in: The system identifies which cluster(s) the query is closest to
Only listings in those clusters are compared to the query
This drastically reduces computation while maintaining quality
For example, consider a search for "pet-friendly cabin near Lake Tahoe with hot tub":
In exact search: The system would compare this query vector to ALL 7+ million Airbnb listings worldwide, measuring the distance to each one.
With IVF: The query first identifies relevant clusters (perhaps "US-West cabins" and "Lake Tahoe region") and only compares against ~10,000 listings in those clusters.
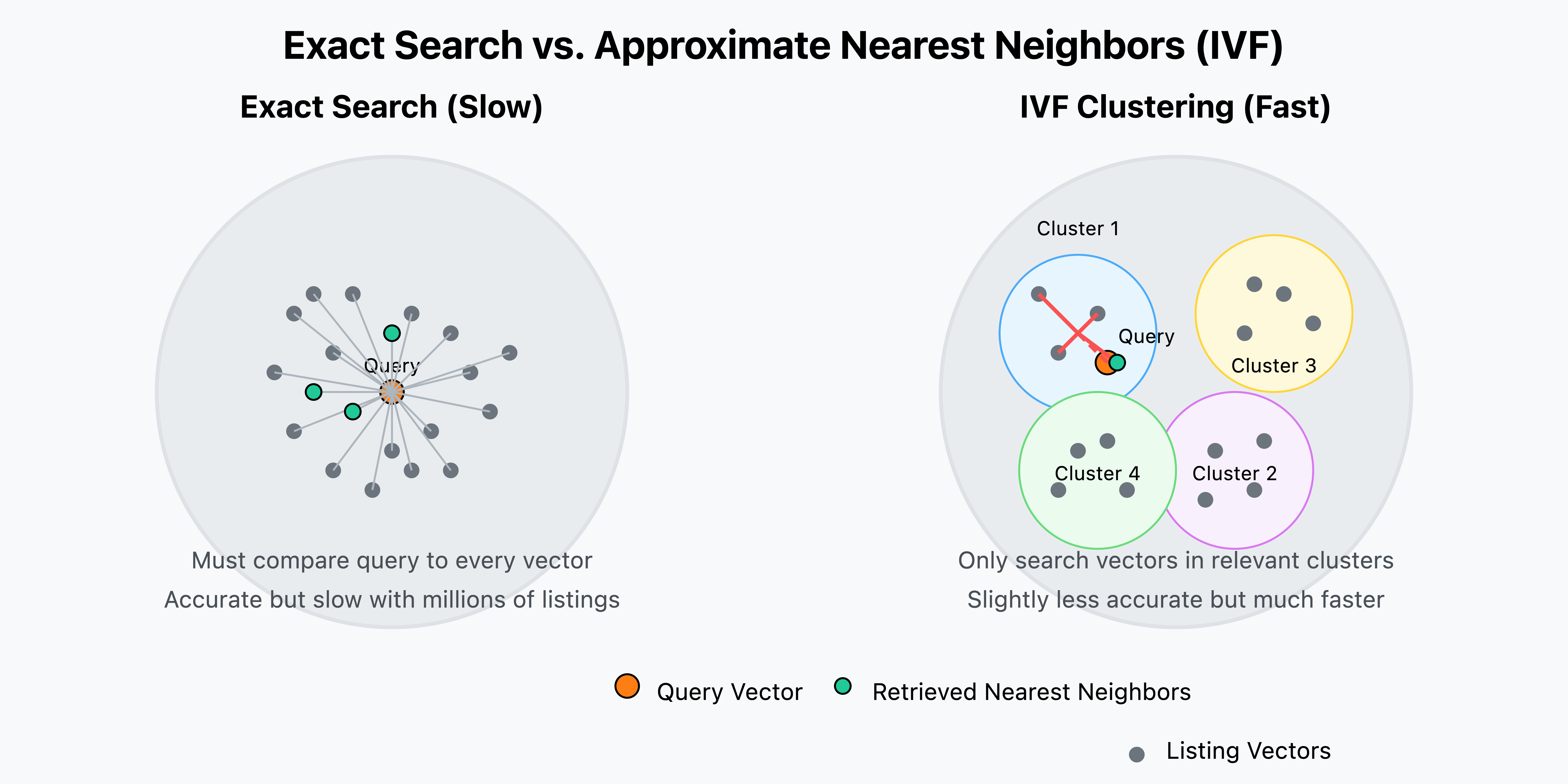
This reduces computation by ~99.9% while still finding listings that are 95-98% as relevant as the exact method would find.
The performance difference is dramatic:
Exact search: 500-1000ms to compare against millions of vectors
IVF search: 10-20ms to find 95% of the same results
This speed allows Airbnb to deliver results almost instantly, while still accounting for all the complex factors that determine a good match.
👉 Key concept: ANN techniques like IVF and HNSW balance speed and accuracy. IVF works well when filtering and memory efficiency matter.
The Role of Similarity Metrics
Airbnb tried two similarity functions:
Dot product: Focuses on direction of vectors (ignores magnitude)
Euclidean distance: Accounts for both direction and magnitude
They found Euclidean distance made better clusters, because many features (like number of past bookings) had magnitude that mattered.
Consider two listings:
Listing A: A new property with 5 bedrooms but only 3 previous bookings
Listing B: A popular property with 3 bedrooms and 300 previous bookings
With dot product, these might seem equally relevant for a "family home" query because they point in similar directions. But with Euclidean distance, the system can better account for the significance of Listing B's booking history as a signal of quality and relevance.
👉 Lesson: The choice of similarity function impacts how vectors are grouped and how well the system retrieves results.
The Results: Better Bookings with Embedding-Based Retrieval
Once launched, Airbnb’s EBR system showed:
A statistically significant lift in bookings
On-par performance with major ranking model improvements — but with faster retrieval
The system particularly excelled with queries returning high volumes of eligible results (like searches for entire regions or popular destinations)
Better personalization and relevance, especially in crowded or vague queries
Final Thoughts
Airbnb’s journey with EBR shows how modern ML techniques can make a huge difference in real-world systems. Key takeaways:
Representing queries and listings in a shared embedding space helps personalize results.
Contrastive training with real user behavior leads to high-quality models.
Smart retrieval (with ANN) makes things fast without losing too much accuracy.
Test Your Knowledge
Each Stacksweep review goes over fundamental questions that come up in interviews and on the job. These test your knowledge to find knowledge gaps. Answers are at the bottom.
If you want to fill out ALL of your knowledge gaps and be fully system-design interview-ready, check out SWE Quiz.
Question 1: What is the primary benefit of using embeddings in information retrieval systems?
A) They reduce the need for machine learning algorithms
B) They represent items numerically in a multi-dimensional space where similar items are close together
C) They eliminate the need for training data
D) They always provide faster retrieval than traditional database queries
Question 2: In contrastive learning for retrieval systems, what is the core training objective?
A) Minimizing the overall size of the embedding space
B) Creating perfectly balanced clusters of all possible items
C) Bringing positive pairs closer together while pushing negative pairs further apart in the embedding space
D) Ensuring all embeddings have the same magnitude regardless of their content
Question 3: What is the fundamental tradeoff when using Approximate Nearest Neighbors (ANN) instead of exact search?
A) Speed versus accuracy
B) Simplicity versus functionality
C) Storage space versus model complexity
D) Training time versus inference time
Question 4: Why is the choice of similarity metric (like dot product vs. Euclidean distance) important in vector search systems?
A) It only affects the computational efficiency of the system
B) It determines which programming languages can be used
C) It influences how the system interprets the relationship between vectors and can impact clustering quality
D) It's purely a matter of convention with no practical differences
Question 5: What is the key tradeoff when designing a two-tower architecture for embedding-based retrieval?
A) Model complexity versus interpretability
B) Compute efficiency versus representation quality
C) Training time versus inference time
D) Vector dimensionality versus storage requirements
Answers
Question 1: B
Explanation: Embeddings transform items (like documents, images, or queries) into numerical vectors in a multi-dimensional space where semantic similarity is preserved. This allows systems to find conceptually similar items even when they don't share exact keywords or attributes. For example, "beachfront condo" and "seaside apartment" might use different words but would be close in embedding space because they represent similar concepts.
Question 2: C
Explanation: Contrastive learning works by training a model to recognize similarities and differences between items. The objective is to minimize the distance between items that should be similar (positive pairs) while maximizing the distance between items that should be different (negative pairs). This approach helps models learn meaningful representations that capture nuanced relationships between items beyond simple matching.
Question 3: A
Explanation: The core tradeoff in ANN methods is between speed and accuracy. Exact nearest neighbor search guarantees finding the closest vectors but becomes prohibitively slow with large datasets. ANN methods like IVF and HNSW sacrifice some accuracy (finding "good enough" neighbors rather than the exact best ones) to gain dramatic improvements in search speed—often reducing query time from seconds to milliseconds while still maintaining 95-98% of the quality.
Question 4: C
Explanation: Different similarity metrics emphasize different aspects of vector relationships. Dot product focuses on the direction of vectors while ignoring magnitude, which works well for some applications. Euclidean distance accounts for both direction and magnitude, which can better represent certain features where scale matters (like popularity signals). The choice impacts how vectors are grouped and compared, ultimately affecting retrieval quality and the types of relationships the system can effectively capture.
Question 5: B
Explanation: The fundamental tradeoff in two-tower architectures is between computational efficiency and representation quality. Pre-computing embeddings for one side (e.g., documents or products) enables fast retrieval but means those embeddings can't be dynamically influenced by query-specific information. More sophisticated architectures like cross-attention models can create richer representations that account for interactions between query and item features, but they require significantly more computation at inference time and cannot benefit from the same level of pre-computation. System designers must balance the need for speed and scalability against the richness of the representations.